Value stream inefficiencies often hide behind a facade of excellence.
The most significant systemic risk isn’t underperformance. It’s the institutionalization of tribal knowledge—a state where survival depends on a few individuals who “know where all the bodies are buried.”
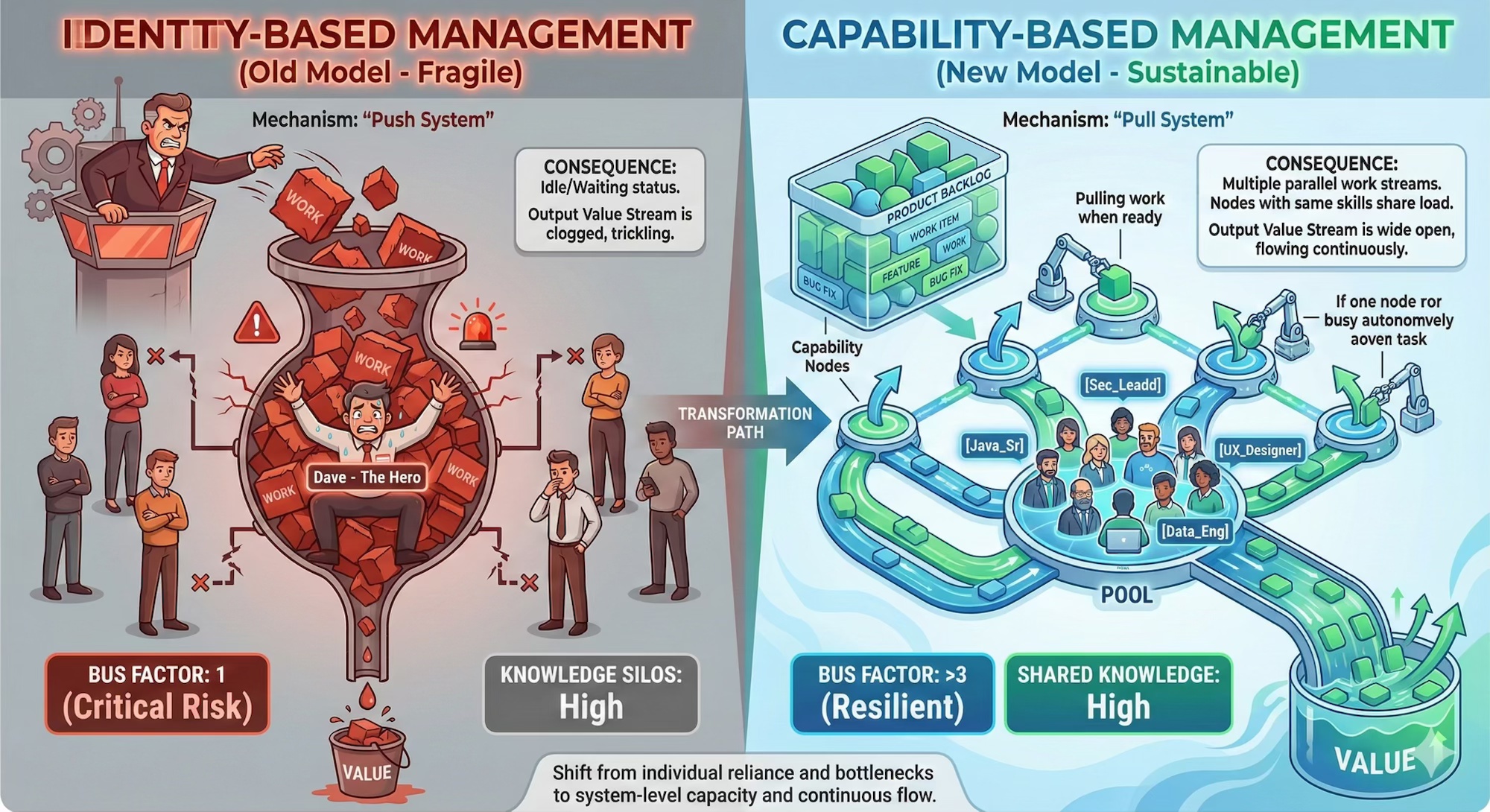
Traditional management misidentifies this as “domain expertise.”
We reward these “top performers” for heroic last-minute saves, failing to see them for what they truly are: Systemic bottlenecks wrapped in human skin. In architecture, a “hero” is simply a Single Point of Failure. If your delivery stalls the moment a specific person takes a vacation, you don’t have a business process. You have a hostage situation.
The “Brent” Trap: Refinancing Technical Debt
As Gene Kim illustrated in The Phoenix Project, the “irreplaceable” expert is actually the greatest threat to flow.
Every time a “Hero” steps in to fix a module only they understand, they are not solving a problem. They are refinancing Technical Debt at a high interest rate. I call this “Architectural Debt”: the delta between relying on a person and a system where any qualified node can execute the task.
If your “A-players” are constantly exhausted, it’s not because the work is hard. It’s because your system is parasitic. It consumes the health of your best people to compensate for a lack of repeatable process.
From Identity to “Units of Capability”
The solution isn’t “people management.” It’s system design.
We must shift from a Push model (assigning tasks to “John”) to a Pull model (presenting work to “Nodes with Capability X”).
• Stop seeing “John.”
• Start seeing a Node with specific Capability Units (e.g., Java_Senior, FinOps_Architect).
| Feature | Identity-Based (Push) | Capability-Based (Pull) |
|---|---|---|
| Assignment Logic | Managerial Intuition / “Who do I trust?” | Systemic Matching / “Who is capable?” |
| Primary Metric | Individual Utilization (%) | Flow Velocity & Throughput |
| Risk Profile | High (Single Points of Failure) | Low (Distributed Capability) |
| Knowledge | Hoarded (as Job Security) | Shared (as Systemic Health) |
| Scalability | Linear (Limited by Heroes) | Exponential (Limited by System) |
This decoupling—as argued in Team Topologies (Skelton & Pais)—reduces cognitive load and removes the “familiarity bias” that keeps 80% of critical tasks on the same three desks.
The Signal in the Stalling
When a critical item sits in the backlog because “no one else can do it,” most managers panic.
In a properly architected system, this is a high-fidelity data signal. An unassigned task is a real-time diagnostic tool exposing a Skill Gap. It should trigger a standardized protocol:
1. Train: Pair the Hero with a Novice immediately.
2. Decompose: Break the task into simpler units.
3. Escalate: Identify the strategic deficit for hiring.
The Insurance Premium of Resilience
Transitioning to a capability-based system isn’t free. It requires an intentional throughput drop.
Focusing on next week’s velocity is a trap. The true ROI of knowledge transfer is found in the Bus Factor (Source: The Mythical Man-Month, Fred Brooks). By investing in pairing and documentation today, you are paying an insurance premium to eliminate personal dependency. You are buying the ability to survive a 12-month horizon with a predictable, smooth flow.
Decouple the Hero, Scale the System
A system’s maturity isn’t measured by how fast it runs with its key members, but by how long it thrives without them.
Nassim Taleb’s Antifragility is the goal. A fragile system breaks under stress. An antifragile organization uses every “unassigned task” as a signal to strengthen its web of capabilities.
Stop rewarding the “Firefighter.” Usually, they are the ones who left the matches lying around by failing to document or mentor.
Instead, incentivize the Architecture. Invest in a system that remains resilient whether you are in the office or halfway across the world.
If you’re still answering emails at 2 AM to solve a technical blocker, you haven’t built a machine. You’ve just built yourself a very expensive, high-stress cage.
Discover more from HOGOFLOW
Subscribe to get the latest posts sent to your email.